Home
Vykar is a fast, encrypted, deduplicated backup tool written in Rust. It’s centered around a simple YAML config format and includes a desktop GUI and webDAV server to browse snapshots. More about design goals.
Do not use for production backups yet, but do test it along other backup tools.
Features
- Storage backends – local filesystem, S3 (any compatible provider), SFTP, dedicated REST server
- Encryption with AES-256-GCM or ChaCha20-Poly1305 (auto-selected) and Argon2id key derivation
- YAML-based configuration with multiple repositories, hooks, and command dumps for monitoring and database backups
- Deduplication via FastCDC content-defined chunking with a memory-optimized engine (tiered dedup index + mmap-backed pack assembly)
- Compression with LZ4 or Zstandard
- Built-in WebDAV and desktop GUI to browse and restore snapshots
- REST server with append-only enforcement, quotas, and server-side compaction
- Concurrent multi-client backups – multiple machines back up to the same repository simultaneously; only the brief commit phase is serialized
- Built-in scheduling via
vykar daemon– runs backup cycles on a configurable interval (no cron needed) - Rate limiting for CPU, disk I/O, and network bandwidth
- Cross-platform – Linux, macOS, and Windows
Benchmarks
Vykar is the fastest tool for both backup and restore, with the lowest CPU cost, while maintaining competitive memory usage.
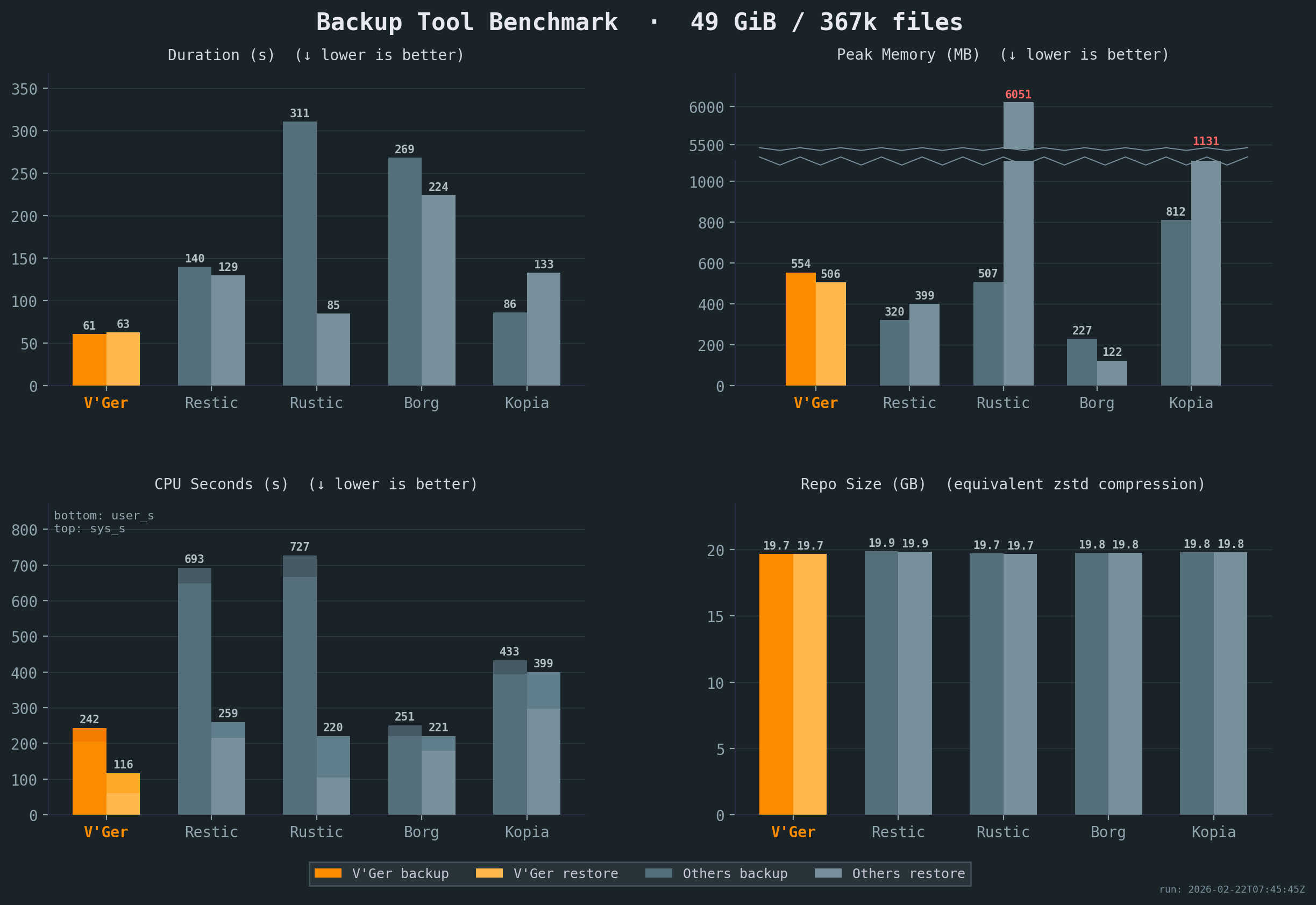
All benchmarks were run 5x on the same idle Intel i7-6700 CPU @ 3.40GHz machine with 2x Samsung PM981 NVMe drives, with results averaged across all runs. Compression settings were chosen to keep resulting repository sizes comparable. The sample corpus is a mix of small and large files with varying compressibility. See detailed results or our benchmark script for full details.
Comparison
| Aspect | Borg | Restic | Rustic | Vykar |
|---|---|---|---|---|
| Configuration | CLI (YAML via Borgmatic) | CLI (YAML via ResticProfile) | TOML config file | YAML config with env-var expansion |
| Browse snapshots | FUSE mount | FUSE mount | FUSE mount | Built-in WebDAV + web UI |
| Command dumps | Via Borgmatic (database-specific) | None | None | Native (generic command capture) |
| Hooks | Via Borgmatic | Via ResticProfile | Native | Native (per-command before/after) |
| Rate limiting | None | Upload/download bandwidth | – | CPU, disk I/O, and network bandwidth |
| Dedicated server | SSH (borg serve) | rest-server (append-only) | rustic_server | REST server with append-only, quotas, server-side compaction |
| Desktop GUI | Vorta (third-party) | Third-party (Backrest) | None | Built-in |
| Scheduling | Via Borgmatic | Via ResticProfile | External (cron/systemd) | Built-in |
| Language | Python + Cython | Go | Rust | Rust |
| Chunker | Buzhash (custom) | Rabin | Rabin (Restic-compat) | FastCDC |
| Encryption | AES-CTR+HMAC / AES-OCB / ChaCha20 | AES-256-CTR + Poly1305-AES | AES-256-CTR + Poly1305-AES | AES-256-GCM / ChaCha20-Poly1305 (auto-select at init) |
| Key derivation | PBKDF2 or Argon2id | scrypt | scrypt | Argon2id |
| Serialization | msgpack | JSON + Protocol Buffers | JSON + Protocol Buffers | msgpack |
| Storage | borgstore + SSH RPC | Local, S3, SFTP, REST, rclone | Local, S3, SFTP, REST | Local, S3, SFTP, REST + vykar-server |
| Repo compatibility | Borg v1/v2/v3 | Restic format | Restic-compatible | Own format |
Inspired by
- BorgBackup: architecture, chunking strategy, repository concept, and overall backup pipeline.
- Borgmatic: YAML configuration approach, pipe-based database dumps.
- Rustic: pack file design and architectural references from a mature Rust backup tool.
- Name: From Latin vicarius (“substitute, stand-in”) — because a backup is literally a substitute for lost data.
Get Started
Follow the Quick Start guide to install Vykar, create a config, and run your first backup in under 5 minutes.
Once you’re up and running:
- Configure storage backends – connect S3, SFTP, or the REST server
- Set up hooks and command dumps – run scripts before/after backups, capture database dumps
- Browse and restore snapshots – list, search, and restore files
- Maintain your repository – prune old snapshots, check integrity, compact packs
- Explore backup recipes – common patterns for databases, containers, and filesystems
Quick Start
Install
Run the install script:
curl -fsSL https://vykar.borgbase.com/install.sh | sh
Or download a pre-built binary from the releases page. See Installing for more details.
Create a config file
Generate a starter config file, then edit it to set your repository path and source directories:
vykar config
Initialize and back up
Initialize the repository (prompts for passphrase if encrypted):
vykar init
Create a backup of all configured sources:
vykar backup
Or back up any folder directly:
vykar backup ~/Documents
Inspect snapshots
List all snapshots:
vykar list
List files inside a snapshot (use the hex ID from vykar list):
vykar snapshot list a1b2c3d4
Search for a file across recent snapshots:
vykar snapshot find --name '*.txt' --since 7d
Restore
Restore files from a snapshot to a directory:
vykar restore a1b2c3d4 /tmp/restored
For backup options, snapshot browsing, and maintenance tasks, see the workflow guides.
Installing
Quick install
curl -fsSL https://vykar.borgbase.com/install.sh | sh
Or download the latest release for your platform from the releases page.
Pre-built binaries
Extract the archive and place the vykar binary somewhere on your PATH:
# Example for Linux/macOS
tar xzf vykar-*.tar.gz
sudo cp vykar /usr/local/bin/
For Windows CLI releases:
Expand-Archive vykar-*.zip -DestinationPath .
Move-Item .\vykar.exe "$env:USERPROFILE\\bin\\vykar.exe"
Add your chosen directory (for example, %USERPROFILE%\bin) to PATH if needed.
Build from source
Requires Rust 1.88 or later.
git clone https://github.com/borgbase/vykar.git
cd vykar
cargo build --release
The binary is at target/release/vykar. Copy it to a directory on your PATH:
cp target/release/vykar /usr/local/bin/
Verify installation
vykar --version
Next steps
Initialize and Set Up a Repository
Generate a configuration file
Create a starter config
vykar config
Or write it to a specific path:
vykar config --dest ~/.config/vykar/config.yaml
Encryption
Encryption is enabled by default (mode: "auto"). During init, vykar benchmarks AES-256-GCM and ChaCha20-Poly1305, chooses one, and stores that concrete mode in the repository config. No config is needed unless you want to force a mode or disable encryption with mode: "none".
The passphrase is requested interactively at init time. You can also supply it via:
VYKAR_PASSPHRASEenvironment variablepasscommandin the config (e.g.passcommand: "pass show vykar")passphrasein the config
Configure repositories and sources
Set the repository URL and the directories to back up:
repositories:
- label: "main"
url: "/backup/repo"
sources:
- "/home/user/documents"
- "/home/user/photos"
See Configuration for all available options.
Initialize the repository
vykar init
This creates the repository structure at the configured URL. For encrypted repositories, you will be prompted to enter a passphrase.
Validate
Confirm the repository was created:
vykar info
Run a first backup and check results:
vykar backup
vykar list
Next steps
Storage Backends
The repository URL in your config determines which backend is used.
| Backend | URL example |
|---|---|
| Local filesystem | /backups/repo |
| S3 / S3-compatible (HTTPS) | s3://endpoint[:port]/bucket/prefix |
| S3 / S3-compatible (HTTP, unsafe) | s3+http://endpoint[:port]/bucket/prefix |
| SFTP | sftp://host/path |
| REST (vykar-server) | https://host/repo |
Transport security
HTTP transport is blocked by default for remote backends.
https://...is accepted by default.http://...(ors3+http://...) requires explicit opt-in withallow_insecure_http: true.
repositories:
- label: "dev-only"
url: "http://localhost:8484/myrepo"
allow_insecure_http: true
Use plaintext HTTP only on trusted local/dev networks.
Local filesystem
Store backups on a local or mounted disk. No extra configuration needed.
repositories:
- label: "local"
url: "/backups/repo"
Accepted URL formats: absolute paths (/backups/repo), relative paths (./repo), or file:///backups/repo.
S3 / S3-compatible
Store backups in Amazon S3 or any S3-compatible service (MinIO, Wasabi, Backblaze B2, etc.). S3 URLs must include an explicit endpoint and bucket path.
AWS S3:
repositories:
- label: "s3"
url: "s3://s3.us-east-1.amazonaws.com/my-bucket/vykar"
region: "us-east-1" # Default if omitted
access_key_id: "AKIA..."
secret_access_key: "..."
S3-compatible (custom endpoint):
The endpoint is always the URL host, and the first path segment is the bucket:
repositories:
- label: "minio"
url: "s3://minio.local:9000/my-bucket/vykar"
region: "us-east-1"
access_key_id: "minioadmin"
secret_access_key: "minioadmin"
S3-compatible over plaintext HTTP (unsafe):
repositories:
- label: "minio-dev"
url: "s3+http://minio.local:9000/my-bucket/vykar"
region: "us-east-1"
access_key_id: "minioadmin"
secret_access_key: "minioadmin"
allow_insecure_http: true
S3 configuration options
| Field | Description |
|---|---|
region | AWS region (default: us-east-1) |
access_key_id | Access key ID (required) |
secret_access_key | Secret access key (required) |
allow_insecure_http | Permit s3+http:// URLs (unsafe; default: false) |
SFTP
Store backups on a remote server via SFTP. Uses a native russh implementation (pure Rust SSH/SFTP) — no system ssh binary required. Works on all platforms including Windows.
Host keys are verified with an OpenSSH known_hosts file. Unknown hosts use TOFU (trust-on-first-use): the first key is stored, and later key changes fail connection.
repositories:
- label: "nas"
url: "sftp://backup@nas.local/backups/vykar"
# sftp_key: "/home/user/.ssh/id_rsa" # Path to private key (optional)
# sftp_known_hosts: "/home/user/.ssh/known_hosts" # Optional known_hosts path
# sftp_max_connections: 4 # Optional concurrency limit (1..=32)
URL format: sftp://[user@]host[:port]/path. Default port is 22.
SFTP configuration options
| Field | Description |
|---|---|
sftp_key | Path to SSH private key (auto-detects ~/.ssh/id_ed25519, id_rsa, id_ecdsa) |
sftp_known_hosts | Path to OpenSSH known_hosts file (default: ~/.ssh/known_hosts) |
sftp_max_connections | Max concurrent SFTP connections (default: 4, clamped to 1..=32) |
REST (vykar-server)
Store backups on a dedicated vykar-server instance via HTTP/HTTPS. The server provides append-only enforcement, quotas, lock management, and server-side compaction.
repositories:
- label: "server"
url: "https://backup.example.com/myrepo"
access_token: "my-secret-token" # Bearer token for authentication
REST configuration options
| Field | Description |
|---|---|
access_token | Bearer token sent as Authorization: Bearer <token> |
allow_insecure_http | Permit http:// REST URLs (unsafe; default: false) |
See Server Setup for how to set up and configure the server.
All backends are included in pre-built binaries from the releases page.
Make a Backup
Run a backup
Back up all configured sources to all configured repositories:
vykar backup
By default, Vykar preserves filesystem extended attributes (xattrs). Configure this globally with xattrs.enabled, and override per source in rich sources entries.
If some files are unreadable or disappear during the run (for example, permission denied or a file vanishes), Vykar skips those files, still creates the snapshot from everything else, and returns exit code 3 to indicate partial success.
Sources and labels
In its simplest form, sources are just a list of paths:
sources:
- /home/user/documents
- /home/user/photos
For more complex situations you can add overrides to source groups. Each “rich” source in your config produces its own snapshot. When you use the rich source form, the label field gives each source a short name you can reference from the CLI:
sources:
- path: "/home/user/photos"
label: "photos"
- paths:
- "/home/user/documents"
- "/home/user/notes"
label: "docs"
exclude: ["*.tmp"]
hooks:
before: "echo starting docs backup"
Back up only a specific source by label:
vykar backup --source docs
When targeting a specific repository, use --repo:
vykar backup --repo local --source docs
Ad-hoc backups
You can still do ad-hoc backups of arbitrary folders and annotate them with a label, for example before a system change:
vykar backup --label before-upgrade /var/www
--label is only valid for ad-hoc backups with explicit path arguments. For example, this is rejected:
vykar backup --label before-upgrade
So you can identify it later in vykar list output.
List and verify snapshots
# List all snapshots
vykar list
# List the 5 most recent snapshots
vykar list --last 5
# List snapshots for a specific source
vykar list --source docs
# List files inside a snapshot
vykar snapshot list a1b2c3d4
# Find recent SQL dumps across recent snapshots
vykar snapshot find --last 5 --name '*.sql'
# Find logs from one source changed in the last week
vykar snapshot find --source myapp --since 7d --iname '*.log'
Command dumps
You can capture the stdout of shell commands directly into your backup using command_dumps. This is useful for database dumps, API exports, or any generated data that doesn’t live as a regular file on disk:
sources:
- path: /var/www/myapp
label: myapp
command_dumps:
- name: postgres.sql
command: pg_dump -U myuser mydb
- name: redis.rdb
command: redis-cli --rdb -
Each command runs via sh -c and the captured output is stored as a virtual file under .vykar-dumps/ in the snapshot. On restore, these appear as regular files:
.vykar-dumps/postgres.sql
.vykar-dumps/redis.rdb
You can also create dump-only sources with no filesystem paths:
sources:
- label: databases
command_dumps:
- name: all-databases.sql
command: pg_dumpall -U postgres
Dump-only sources require an explicit label. If any command exits with a non-zero status, the backup is aborted.
Related pages
Restore a Backup
Locate snapshots
# List all snapshots
vykar list
# List the 5 most recent snapshots
vykar list --last 5
# List snapshots for a specific source
vykar list --source docs
Inspect snapshot contents
# List files inside a snapshot
vykar snapshot list a1b2c3d4
# List with details (type, permissions, size, mtime)
vykar snapshot list a1b2c3d4 --long
# Limit listing to a subtree
vykar snapshot list a1b2c3d4 --path src
# Sort listing by size (name, size, mtime)
vykar snapshot list a1b2c3d4 --sort size
Inspect snapshot metadata
vykar snapshot info a1b2c3d4
Find files across snapshots
Use snapshot find to locate files before choosing which snapshot to restore from.
# Find PDFs modified in the last 14 days
vykar snapshot find --name '*.pdf' --since 14d
# Limit search to one source and recent snapshots
vykar snapshot find --source docs --last 10 --name '*.docx'
# Search under a subtree with case-insensitive name matching
vykar snapshot find sub --iname 'report*' --since 7d
# Combine type and size filters
vykar snapshot find --type f --larger 1M --smaller 20M --since 30d
--lastmust be>= 1.--sinceaccepts positive spans with suffixh,d, orw(for example:24h,7d,2w).--largermeans at least this size, and--smallermeans at most this size.
Restore to a directory
# Restore all files from a snapshot
vykar restore a1b2c3d4 /tmp/restored
# Restore the most recent snapshot
vykar restore latest /tmp/restored
Restore applies extended attributes (xattrs) by default. Control this with the top-level xattrs.enabled config setting.
Browse via WebDAV (mount)
Browse snapshot contents via a local WebDAV server.
# Serve all snapshots (default: http://127.0.0.1:8080)
vykar mount
# Serve a single snapshot
vykar mount --snapshot a1b2c3d4
# Only snapshots from a specific source
vykar mount --source docs
# Custom listen address
vykar mount --address 127.0.0.1:9090
Related pages
Maintenance
Delete a snapshot
# Delete a specific snapshot by ID
vykar snapshot delete a1b2c3d4
Delete a repository
Permanently delete an entire repository and all its snapshots.
# Interactive confirmation (prompts you to type "delete")
vykar delete
# Non-interactive (for scripting)
vykar delete --yes-delete-this-repo
Prune old snapshots
Apply the retention policy defined in your configuration to remove expired snapshots. Optionally compact the repository after pruning.
vykar prune --compact
Verify repository integrity
# Structural integrity check
vykar check
# Full data verification (reads and verifies every chunk)
vykar check --verify-data
Compact (reclaim space)
After delete or prune, blob data remains in pack files. Run compact to rewrite packs and reclaim disk space.
# Preview what would be repacked
vykar compact --dry-run
# Repack to reclaim space
vykar compact
Related pages
- Quick Start
- Server Setup (server-side compaction)
- Architecture (compact algorithm details)
Backup Recipes
Vykar provides hooks, command dumps, and source directories as universal building blocks. Rather than adding dedicated flags for each database or container runtime, the same patterns work for any application.
These recipes are starting points — adapt the commands to your setup.
Databases
Databases should never be backed up by copying their data files while running. Use the database’s own dump tool to produce a consistent export.
Where possible, use command dumps — they stream stdout directly into the backup without temporary files. For tools that can’t stream to stdout, use hooks to dump to a temporary directory, back it up, then clean up.
PostgreSQL
sources:
- label: postgres
command_dumps:
- name: mydb.dump
command: "pg_dump -U myuser -Fc mydb"
For all databases at once:
sources:
- label: postgres
command_dumps:
- name: all.sql
command: "pg_dumpall -U postgres"
If you need to run additional steps around the dump (e.g. custom authentication, pre/post scripts), use hooks instead. Note that this saves the dump to disk instead of reading it directly with the command_dump feature.
sources:
- path: /var/backups/postgres
label: postgres
hooks:
before: >
mkdir -p /var/backups/postgres &&
pg_dump -U myuser -Fc mydb > /var/backups/postgres/mydb.dump
after: "rm -rf /var/backups/postgres"
MySQL / MariaDB
sources:
- label: mysql
command_dumps:
- name: all.sql
command: "mysqldump -u root -p\"$MYSQL_ROOT_PASSWORD\" --all-databases"
With hooks:
sources:
- path: /var/backups/mysql
label: mysql
hooks:
before: >
mkdir -p /var/backups/mysql &&
mysqldump -u root -p"$MYSQL_ROOT_PASSWORD" --all-databases
> /var/backups/mysql/all.sql
after: "rm -rf /var/backups/mysql"
MongoDB
sources:
- label: mongodb
command_dumps:
- name: mydb.archive.gz
command: "mongodump --archive --gzip --db mydb"
For all databases, omit --db:
sources:
- label: mongodb
command_dumps:
- name: all.archive.gz
command: "mongodump --archive --gzip"
SQLite
SQLite can’t stream to stdout, so use a hook. Copying the database file directly risks corruption if a process holds a write lock.
sources:
- path: /var/backups/sqlite
label: app-database
hooks:
before: >
mkdir -p /var/backups/sqlite &&
sqlite3 /var/lib/myapp/app.db ".backup '/var/backups/sqlite/app.db'"
after: "rm -rf /var/backups/sqlite"
Redis
sources:
- path: /var/backups/redis
label: redis
hooks:
before: >
mkdir -p /var/backups/redis &&
redis-cli BGSAVE &&
sleep 2 &&
cp /var/lib/redis/dump.rdb /var/backups/redis/dump.rdb
after: "rm -rf /var/backups/redis"
The sleep gives Redis time to finish the background save. For large datasets, check redis-cli LASTSAVE in a loop instead.
Docker and Containers
The same patterns work for containerized applications. Use docker exec for command dumps and hooks, or back up Docker volumes directly from the host.
These examples use Docker, but the same approach works with Podman or any other container runtime.
Docker volumes (static data)
For volumes that hold files not actively written to by a running process — configuration, uploaded media, static assets — back up the host path directly.
sources:
- path: /var/lib/docker/volumes/myapp_data/_data
label: myapp
Note: The default volume path
/var/lib/docker/volumes/applies to standard Docker installs on Linux. It differs for Docker Desktop on macOS/Windows, rootless Docker, Podman (/var/lib/containers/storage/volumes/for root,~/.local/share/containers/storage/volumes/for rootless), and customdata-rootconfigurations. Rundocker volume inspect <n>orpodman volume inspect <n>to find the actual path.
Docker volumes with brief downtime
For applications that write to the volume but can tolerate a short stop, stop the container during backup.
sources:
- path: /var/lib/docker/volumes/wiki_data/_data
label: wiki
hooks:
before: "docker stop wiki"
finally: "docker start wiki"
Database containers
Use command dumps with docker exec to stream database exports directly from a container.
PostgreSQL in Docker:
sources:
- label: app-database
command_dumps:
- name: mydb.dump
command: "docker exec my-postgres pg_dump -U myuser -Fc mydb"
MySQL / MariaDB in Docker:
sources:
- label: app-database
command_dumps:
- name: mydb.sql
command: "docker exec my-mysql mysqldump -u root -p\"$MYSQL_ROOT_PASSWORD\" mydb"
MongoDB in Docker:
sources:
- label: app-database
command_dumps:
- name: mydb.archive.gz
command: "docker exec my-mongo mongodump --archive --gzip --db mydb"
Multiple containers
Use separate source entries so each service gets its own label, retention policy, and hooks.
sources:
- path: /var/lib/docker/volumes/nginx_config/_data
label: nginx
retention:
keep_daily: 7
- label: app-database
command_dumps:
- name: mydb.dump
command: "docker exec my-postgres pg_dump -U myuser -Fc mydb"
retention:
keep_daily: 30
- path: /var/lib/docker/volumes/uploads/_data
label: uploads
Virtual Machine Disk Images
Virtual machine disk images are an excellent use case for deduplicated backups. Large portions of a VM’s disk remain unchanged between snapshots, so Vykar’s content-defined chunking achieves high deduplication ratios — often reducing storage to a fraction of the raw image size.
Prerequisites
The guest VM must have the QEMU guest agent installed and running, and QEMU must be started with a guest agent socket (e.g. -chardev socket,path=/tmp/qga.sock,server=on,wait=off,id=qga0). Install socat on the host if not already present.
Freeze, Backup, Thaw
Use hooks to freeze the guest filesystem before backing up the disk image, then thaw it afterwards:
sources:
- path: /var/lib/libvirt/images
label: vm-images
hooks:
before: >
echo '{"execute":"guest-fsfreeze-freeze"}' |
socat - unix-connect:/tmp/qga.sock
finally: >
echo '{"execute":"guest-fsfreeze-thaw"}' |
socat - unix-connect:/tmp/qga.sock
The freeze ensures the filesystem is in a clean state while Vykar reads the image. For incremental backups (every run after the first), only changed chunks are processed, so the freeze window is short.
Tips
- Raw images dedup better than qcow2. The qcow2 format uses internal copy-on-write structures that can shuffle data, reducing byte-level similarity between snapshots. If practical, convert with
qemu-img convert -f qcow2 -O raw. - Multiple VMs in one repo provides cross-VM deduplication. VMs running the same OS share many common chunks.
- For environments that cannot tolerate any guest I/O pause, use QEMU external snapshots instead. This redirects writes to an overlay file via QMP
blockdev-snapshot-sync, allowing the base image to be backed up with zero interruption. This is the approach used by Proxmox VE and libvirt.
Filesystem Snapshots
For filesystems that support snapshots, the safest approach is to snapshot first, back up the snapshot, then delete it. This gives you a consistent point-in-time view without stopping any services.
Btrfs
sources:
- path: /mnt/.snapshots/data-backup
label: data
hooks:
before: "btrfs subvolume snapshot -r /mnt/data /mnt/.snapshots/data-backup"
after: "btrfs subvolume delete /mnt/.snapshots/data-backup"
The snapshot parent directory (/mnt/.snapshots/) must exist before the first backup. Create it once:
mkdir -p /mnt/.snapshots
ZFS
sources:
- path: /tank/data/.zfs/snapshot/vykar-tmp
label: data
hooks:
before: "zfs snapshot tank/data@vykar-tmp"
after: "zfs destroy tank/data@vykar-tmp"
Important: The
.zfs/snapshotdirectory is only accessible ifsnapdiris set tovisibleon the dataset. This is not the default. Set it before using this recipe:zfs set snapdir=visible tank/data
LVM
sources:
- path: /mnt/lvm-snapshot
label: data
hooks:
before: >
lvcreate -s -n vykar-snap -L 5G /dev/vg0/data &&
mkdir -p /mnt/lvm-snapshot &&
mount -o ro /dev/vg0/vykar-snap /mnt/lvm-snapshot
after: >
umount /mnt/lvm-snapshot &&
lvremove -f /dev/vg0/vykar-snap
Set the snapshot size (-L 5G) large enough to hold changes during the backup.
Low-Resource Background Backup
If backups should run in the background with minimal impact on interactive work, use conservative resource limits. This will usually increase backup duration.
compression:
algorithm: lz4
limits:
cpu:
max_threads: 1
nice: 19
max_upload_concurrency: 1
pipeline_depth: 0
transform_batch_mib: 4
transform_batch_chunks: 256
io:
read_mib_per_sec: 8
write_mib_per_sec: 4
network:
read_mib_per_sec: 4
write_mib_per_sec: 2
max_threads: 1andpipeline_depth: 0keep backup processing mostly sequential.nice: 19lowers CPU scheduling priority on Unix; it is ignored on Windows.max_upload_concurrency: 1avoids bursts from parallel uploads.io.*andnetwork.*cap throughput in MiB/s; lower values reduce impact further.- If this is too slow, increase
io.read_mib_per_secandnetwork.write_mib_per_secfirst.
Monitoring
Vykar hooks can notify monitoring services on success or failure. A curl in an after hook replaces the need for dedicated integrations.
Healthchecks
Healthchecks alerts you when backups stop arriving. Ping the check URL after each successful backup.
hooks:
after: "curl -fsS -m 10 --retry 5 https://hc-ping.com/your-uuid-here"
To report failures too, use separate success and failure URLs:
hooks:
after: "curl -fsS -m 10 --retry 5 https://hc-ping.com/your-uuid-here"
failed: "curl -fsS -m 10 --retry 5 https://hc-ping.com/your-uuid-here/fail"
ntfy
ntfy sends push notifications to your phone. Useful for immediate failure alerts.
hooks:
failed: >
curl -fsS -m 10
-H "Title: Backup failed"
-H "Priority: high"
-H "Tags: warning"
-d "vykar backup failed on $(hostname)"
https://ntfy.sh/my-backup-alerts
Uptime Kuma
Uptime Kuma is a self-hosted monitoring tool. Use a push monitor to track backup runs.
hooks:
after: "curl -fsS -m 10 http://your-kuma-instance:3001/api/push/your-token?status=up"
Generic webhook
Any service that accepts HTTP requests works the same way.
hooks:
after: >
curl -fsS -m 10 -X POST
-H "Content-Type: application/json"
-d '{"text": "Backup completed on $(hostname)"}'
https://hooks.slack.com/services/your/webhook/url
Configuration
Vykar is driven by a YAML configuration file. Generate a starter config with:
vykar config
Config file locations
Vykar automatically finds config files in this order:
--config <path>flagVYKAR_CONFIGenvironment variable./vykar.yaml(project)- User config dir +
vykar/config.yaml:- Unix:
$XDG_CONFIG_HOME/vykar/config.yamlor~/.config/vykar/config.yaml - Windows:
%APPDATA%\\vykar\\config.yaml
- Unix:
- System config:
- Unix:
/etc/vykar/config.yaml - Windows:
%PROGRAMDATA%\\vykar\\config.yaml
- Unix:
You can also set VYKAR_PASSPHRASE to supply the passphrase non-interactively.
Minimal example
A complete but minimal working config. Encryption defaults to auto (init benchmarks AES-256-GCM vs ChaCha20-Poly1305 and pins the repo), so you only need repositories and sources:
repositories:
- url: "/backup/repo"
sources:
- "/home/user/documents"
Repositories
Local:
repositories:
- label: "local"
url: "/backups/repo"
S3:
repositories:
- label: "s3"
url: "s3://s3.us-east-1.amazonaws.com/my-bucket/vykar"
region: "us-east-1"
access_key_id: "AKIA..."
secret_access_key: "..."
Each entry accepts an optional label for CLI targeting (vykar list --repo local) and optional pack size tuning (min_pack_size, max_pack_size). Defaults are min_pack_size = 32 MiB and max_pack_size = 128 MiB; max_pack_size has a hard ceiling of 512 MiB. See Storage Backends for all backend-specific options.
For remote repositories, transport is HTTPS-first by default. To intentionally use plaintext HTTP (for local/dev setups), set:
repositories:
- url: "http://localhost:8484/myrepo"
allow_insecure_http: true
For S3-compatible HTTP endpoints, use s3+http://... URLs with allow_insecure_http: true.
Multiple repositories
Add more entries to repositories: to back up to multiple destinations. Top-level settings serve as defaults; each entry can override encryption, compression, retention, and limits.
repositories:
- label: "local"
url: "/backups/local"
- label: "remote"
url: "s3://s3.us-east-1.amazonaws.com/bucket/remote"
region: "us-east-1"
access_key_id: "AKIA..."
secret_access_key: "..."
encryption:
passcommand: "pass show vykar-remote"
compression:
algorithm: "zstd" # Better ratio for remote
retention:
keep_daily: 30 # Keep more on remote
limits:
cpu:
max_threads: 2
network:
write_mib_per_sec: 25
When limits is set on a repository entry, it replaces top-level limits for that repository.
By default, commands operate on all repositories. Use --repo / -R to target a single one:
vykar list --repo local
vykar list -R /backups/local
3-2-1 backup strategy
Tip: Configuring both a local and a remote repository gives you a 3-2-1 backup setup: three copies of your data (the original files, the local backup, and the remote backup), on two different media types, with one copy offsite. The example above already achieves this.
Sources
Sources can be a simple list of paths (auto-labeled from directory name) or rich entries with per-source options.
Simple form:
sources:
- "/home/user/documents"
- "/home/user/photos"
Rich form (single path):
sources:
- path: "/home/user/documents"
label: "docs"
exclude: ["*.tmp", ".cache/**"]
# exclude_if_present: [".nobackup", "CACHEDIR.TAG"]
# one_file_system: true
# git_ignore: false
repos: ["main"] # Only back up to this repo (default: all)
retention:
keep_daily: 7
hooks:
before: "echo starting docs backup"
Rich form (multiple paths):
Use paths (plural) to group several directories into a single source. An explicit label is required:
sources:
- paths:
- "/home/user/documents"
- "/home/user/notes"
label: "writing"
exclude: ["*.tmp"]
These directories are backed up together as one snapshot. You cannot use both path and paths on the same entry.
Per-source overrides
Each source entry in rich form can override global settings. This lets you tailor backup behavior per directory:
sources:
- path: "/home/user/documents"
label: "docs"
exclude: ["*.tmp"]
xattrs:
enabled: false # Override top-level xattrs setting for this source
repos: ["local"] # Only back up to the "local" repo
retention:
keep_daily: 7
keep_weekly: 4
- path: "/home/user/photos"
label: "photos"
repos: ["local", "remote"] # Back up to both repos
retention:
keep_daily: 30
keep_monthly: 12
hooks:
after: "echo photos backed up"
Per-source fields that override globals: exclude, exclude_if_present, one_file_system, git_ignore, repos, retention, hooks, command_dumps.
Command Dumps
Capture the stdout of shell commands directly into your backup. Useful for database dumps, API exports, or any generated data that doesn’t live as a regular file on disk.
sources:
- path: /var/www/myapp
label: myapp
command_dumps:
- name: postgres.sql
command: pg_dump -U myuser mydb
- name: redis.rdb
command: redis-cli --rdb -
Each entry has two required fields:
| Field | Description |
|---|---|
name | Virtual filename (e.g. mydb.sql). Must not contain / or \. No duplicates within a source. |
command | Shell command whose stdout is captured (run via sh -c). |
Output is stored as virtual files under .vykar-dumps/ in the snapshot. On restore they appear as regular files (e.g. .vykar-dumps/postgres.sql).
You can also create dump-only sources with no filesystem paths — an explicit label is required:
sources:
- label: databases
command_dumps:
- name: all-databases.sql
command: pg_dumpall -U postgres
If a dump command exits with non-zero status, the backup is aborted. Any chunks already uploaded to packs remain on disk but are not added to the index; they are reclaimed on the next vykar compact run.
See Backup — Command dumps for more details and Recipes for PostgreSQL, MySQL, MongoDB, and Docker examples.
Encryption
Encryption is enabled by default (auto mode with Argon2id key derivation). You only need an encryption section to supply a passcommand, force a specific algorithm, or disable encryption:
encryption:
# mode: "auto" # Default — benchmark at init and persist chosen mode
# mode: "aes256gcm" # Force AES-256-GCM
# mode: "chacha20poly1305" # Force ChaCha20-Poly1305
# mode: "none" # Disable encryption
# passphrase: "inline-secret" # Not recommended for production
# passcommand: "pass show borg" # Shell command that prints the passphrase
none mode requires no passphrase and creates no key file. Data is still checksummed via keyed BLAKE2b-256 chunk IDs to detect storage corruption, but is not authenticated against tampering. See Architecture — Plaintext Mode for details.
passcommand runs through the platform shell:
- Unix:
sh -c - Windows:
powershell -NoProfile -NonInteractive -Command
Compression
compression:
algorithm: "lz4" # "lz4", "zstd", or "none"
zstd_level: 3 # Only used with zstd
Chunker
chunker: # Optional, defaults shown
min_size: 524288 # 512 KiB
avg_size: 2097152 # 2 MiB
max_size: 8388608 # 8 MiB
Exclude Patterns
exclude_patterns: # Global gitignore-style patterns (merged with per-source)
- "*.tmp"
- ".cache/**"
exclude_if_present: # Skip dirs containing any marker file
- ".nobackup"
- "CACHEDIR.TAG"
one_file_system: false # Do not cross filesystem/mount boundaries (default false)
git_ignore: false # Respect .gitignore files (default false)
xattrs: # Extended attribute handling
enabled: true # Preserve xattrs on backup/restore (default true, Unix-only)
Retention
retention: # Global retention policy (can be overridden per-source)
keep_last: 10
keep_daily: 7
keep_weekly: 4
keep_monthly: 6
keep_yearly: 2
keep_within: "2d" # Keep everything within this period (e.g. "2d", "48h", "1w")
Compact
compact:
threshold: 20 # Minimum % unused space to trigger repack (default 20)
Limits
limits: # Optional backup resource limits
cpu:
max_threads: 0 # 0 = default rayon behavior
nice: 0 # Unix niceness target (-20..19), ignored on Windows
max_upload_concurrency: 2 # In-flight pack uploads to remote backends (1-16)
io:
read_mib_per_sec: 0 # Source file reads during backup
write_mib_per_sec: 0 # Local repository writes during backup
network:
read_mib_per_sec: 0 # Remote backend reads during backup
write_mib_per_sec: 0 # Remote backend writes during backup
Hooks
Shell commands that run at specific points in the vykar command lifecycle. Hooks can be defined at three levels: global (top-level hooks:), per-repository, and per-source.
hooks: # Global hooks: run for backup/prune/check/compact
before: "echo starting"
after: "echo done"
# before_backup: "echo backup starting" # Command-specific hooks
# failed: "notify-send 'vykar failed'"
# finally: "cleanup.sh"
Hook types
| Hook | Runs when | Failure behavior |
|---|---|---|
before / before_<cmd> | Before the command | Aborts the command |
after / after_<cmd> | After success only | Logged, doesn’t affect result |
failed / failed_<cmd> | After failure only | Logged, doesn’t affect result |
finally / finally_<cmd> | Always, regardless of outcome | Logged, doesn’t affect result |
Hooks only run for backup, prune, check, and compact. The bare form (before, after, etc.) fires for all four commands, while the command-specific form (before_backup, failed_prune, etc.) fires only for that command.
Execution order
beforehooks run: global bare → repo bare → global specific → repo specific- The vykar command runs (skipped if a
beforehook fails) - On success:
afterhooks run (repo specific → global specific → repo bare → global bare) On failure:failedhooks run (same order) finallyhooks always run last (same order)
If a before hook fails, the command is skipped and both failed and finally hooks still run.
Variable substitution
Hook commands support {variable} placeholders that are replaced before execution. Values are automatically shell-escaped.
| Variable | Description |
|---|---|
{command} | The vykar command name (e.g. backup, prune) |
{repository} | Repository URL |
{label} | Repository label (empty if unset) |
{error} | Error message (empty if no error) |
{source_label} | Source label (empty if unset) |
{source_path} | Source path list (Unix :, Windows ;) |
The same values are also exported as environment variables: VYKAR_COMMAND, VYKAR_REPOSITORY, VYKAR_LABEL, VYKAR_ERROR, VYKAR_SOURCE_LABEL, VYKAR_SOURCE_PATH.
{source_path} / VYKAR_SOURCE_PATH joins multiple paths with : on Unix and ; on Windows.
hooks:
failed:
- 'notify-send "vykar {command} failed: {error}"'
after_backup:
- 'echo "Backed up {source_label} to {repository}"'
Notifications with Apprise
Apprise lets you send notifications to 100+ services (Gotify, Slack, Discord, Telegram, ntfy, email, and more) from the command line. Since vykar hooks run arbitrary shell commands, you can use the apprise CLI directly — no built-in integration needed.
Install it with:
pip install apprise
Then add hooks that call apprise with the service URLs you want:
hooks:
after_backup:
- >-
apprise -t "Backup complete"
-b "vykar {command} finished for {repository}"
"gotify://hostname/token"
"slack://tokenA/tokenB/tokenC"
failed:
- >-
apprise -t "Backup failed"
-b "vykar {command} failed for {repository}: {error}"
"gotify://hostname/token"
Common service URL examples:
| Service | URL format |
|---|---|
| Gotify | gotify://hostname/token |
| Slack | slack://tokenA/tokenB/tokenC |
| Discord | discord://webhook_id/webhook_token |
| Telegram | tgram://bot_token/chat_id |
| ntfy | ntfy://topic |
mailto://user:pass@gmail.com |
You can pass multiple URLs in a single command to notify several services at once. See the Apprise wiki for the full list of supported services and URL formats.
Schedule
Configure the built-in daemon scheduler for automatic periodic backups. Used with vykar daemon.
schedule:
enabled: true # Enable scheduled backups (default false)
every: "6h" # Interval between runs: "30m", "6h", "2d", or integer days (default "24h")
on_startup: false # Run a backup immediately when the daemon starts (default false)
jitter_seconds: 0 # Random delay 0–N seconds added to each interval (default 0)
passphrase_prompt_timeout_seconds: 300 # Timeout for interactive passphrase prompts (default 300)
The every field accepts m (minutes), h (hours), or d (days) suffixes; a plain integer is treated as days.
When multiple repositories are configured, schedule values are merged: enabled and on_startup are OR’d across repos, jitter_seconds and passphrase_prompt_timeout_seconds take the maximum, and every uses the shortest interval.
Environment Variable Expansion
Config files support environment variable placeholders in values:
repositories:
- url: "${VYKAR_REPO_URL:-/backup/repo}"
# access_token: "${VYKAR_ACCESS_TOKEN}"
Supported syntax:
${VAR}: requiresVARto be set (hard error if missing)${VAR:-default}: usesdefaultwhenVARis unset or empty
Notes:
- Expansion runs on raw config text before YAML parsing.
- Variable names must match
[A-Za-z_][A-Za-z0-9_]*. - Malformed placeholders fail config loading.
- No escape syntax is supported for literal
${...}.
Command Reference
| Command | Description |
|---|---|
vykar | Run full backup process: backup, prune, compact, check. This is useful for automation. |
vykar config | Generate a starter configuration file |
vykar init | Initialize a new backup repository |
vykar backup | Back up files to a new snapshot |
vykar restore | Restore files from a snapshot |
vykar list | List snapshots |
vykar snapshot list | Show files and directories inside a snapshot |
vykar snapshot info | Show metadata for a snapshot |
vykar snapshot find | Find matching files across snapshots and show change timeline (added, modified, unchanged) |
vykar snapshot delete | Delete a specific snapshot |
vykar delete | Delete an entire repository permanently |
vykar prune | Prune snapshots according to retention policy |
vykar break-lock | Remove stale repository locks left by interrupted processes when lock conflicts block operations |
vykar check | Verify repository integrity (--verify-data for full content verification) |
vykar info | Show repository statistics (snapshot counts and size totals) |
vykar compact | Free space by repacking pack files after delete/prune |
vykar mount | Browse snapshots via a local WebDAV server |
Exit codes
0: Success1: Error (command failed)3: Partial success (backup completed, but one or more files were skipped)
vykar backup and the default vykar workflow can return 3 when a backup succeeds with skipped unreadable/missing files.
Design Goals
Vykar synthesizes the best ideas from a decade of backup tool development into a single Rust binary. These are the principles behind its design.
One tool, not an assembly
Configuration, scheduling, monitoring, hooks, and health checks belong in the backup tool itself — not in a constellation of wrappers and scripts bolted on after the fact.
Config-first
Your entire backup strategy lives in a single YAML file that can be version-controlled, reviewed, and deployed across machines. A repository path and a list of sources is enough to get going.
repositories:
- url: /backups/myrepo
sources:
- path: /home/user/documents
- path: /home/user/photos
Universal primitives over specific integrations
Vykar doesn’t have dedicated flags for specific databases or services. Instead, hooks and command dumps let you capture the output of any command — the same mechanism works for every database, container, or workflow.
sources:
- path: /var/backups/db
label: databases
hooks:
before: "pg_dump -Fc mydb > /var/backups/db/mydb.dump"
after: "rm -f /var/backups/db/mydb.dump"
Labels, not naming schemes
Snapshots get auto-generated IDs. Labels like personal or databases represent what you’re backing up and group snapshots for retention, filtering, and restore — without requiring unique names or opaque hashes.
vykar list -S databases --last 5
vykar restore --source personal latest
Encryption by default
Encryption is always on. Vykar auto-selects AES-256-GCM or ChaCha20-Poly1305 based on hardware support. Chunk IDs use keyed hashing to prevent content fingerprinting against the repository.
The repository is untrusted
All data is encrypted and authenticated before it leaves the client. The optional REST server enforces append-only access and quotas, so even a compromised client cannot delete historical backups.
Browse without dependencies
vykar mount starts a built-in WebDAV server and web interface. Browse and restore snapshots from any browser or file manager — on any platform, in containers, with zero external dependencies.
Performance through Rust
No GIL bottleneck, no garbage collection pauses, predictable memory usage. FastCDC chunking, parallel compression, and streaming uploads keep the pipeline saturated. Built-in rate limiting for CPU, disk I/O, and network lets Vykar run during business hours.
Discoverability in the CLI
Common operations are short top-level commands. Everything targeting a specific snapshot lives under vykar snapshot. Flags are consistent everywhere: -R is always a repository, -S is always a source label.
vykar backup
vykar list
vykar snapshot find -name "*.xlsx"
vykar snapshot diff a3f7c2 b8d4e1
No lock-in
The repository format is documented, the source is open under GPL-3.0 license, and the REST server is optional. The config is plain YAML with no proprietary syntax.
Architecture
Technical reference for vykar’s cryptographic, chunking, compression, and storage design decisions.
Cryptography
Encryption
AEAD with 12-byte random nonces (AES-256-GCM or ChaCha20-Poly1305).
Rationale:
- Authenticated encryption with modern, audited constructions
automode benchmarksAES-256-GCMvsChaCha20-Poly1305at init and stores one concrete mode per repo- Strong performance across mixed CPU capabilities (AES acceleration and non-AES acceleration)
- 32-byte symmetric keys (simpler key management than split-key schemes)
- AEAD AAD always includes the 1-byte type tag; for identity-bound objects it also includes a domain-separated object context (for example:
manifest,index, snapshot ID, chunk ID, orfilecache)
Plaintext Mode (none)
When encryption is set to none, vykar uses a PlaintextEngine — an identity transform where encrypt() and decrypt() return data unchanged. AAD is ignored (there is no AEAD construction to bind it to). The format layer detects plaintext mode via is_encrypting() == false and uses the shorter wire format: [1-byte type_tag][plaintext] (1-byte overhead instead of 29 bytes).
This mode does not provide authentication or tamper protection — it is designed for trusted storage where confidentiality is unnecessary. Data integrity against accidental corruption is still provided via keyed BLAKE2b-256 chunk IDs (see Hashing / Chunk IDs below).
Key Derivation
Argon2id for passphrase-to-key derivation.
Rationale:
- Modern memory-hard KDF recommended by OWASP and IETF
- Resists both GPU and ASIC brute-force attacks
In none mode no passphrase or key file is needed. The chunk_id_key is deterministically derived as BLAKE2b-256(repo_id). Since repo_id is stored unencrypted in the repo config, this key is not secret — it exists only so that the same keyed hashing path is used in all modes. No keys/repokey file is created.
Hashing / Chunk IDs
Keyed BLAKE2b-256 MAC using a chunk_id_key derived from the master key.
Rationale:
- Prevents content confirmation attacks (an adversary cannot check whether known plaintext exists in the backup without the key)
- BLAKE2b is faster than SHA-256 in software
- Trade-off: keyed IDs prevent dedup across different encryption keys (acceptable for vykar’s single-key-per-repo model)
In none mode the same keyed BLAKE2b-256 construction is used, but the key is derived from the public repo_id rather than a secret master key. The MAC therefore acts as a checksum for corruption detection, not as authentication against tampering. vykar check --verify-data recomputes chunk IDs and compares them to detect bit-rot or storage corruption — this works identically across all encryption modes.
Content Processing
Chunking
FastCDC (content-defined chunking) via the fastcdc v3 crate.
Default parameters: 512 KiB min, 2 MiB average, 8 MiB max (configurable in YAML).
chunker.max_size is hard-capped at 16 MiB during config validation.
Rationale:
- Newer algorithm, benchmarks faster than Rabin fingerprinting
- Good deduplication ratio with configurable chunk boundaries
Compression
Per-chunk compression with a 1-byte tag prefix. Supported algorithms: LZ4, ZSTD, and None.
Rationale:
- Per-chunk tags allow mixing algorithms within a single repository
- LZ4 for speed-sensitive workloads, ZSTD for better compression ratios
- No repository-wide format version lock-in for compression choice
- ZSTD compression reuses a thread-local compressor context per level, reducing allocation churn in parallel backup paths
- Decompression enforces a hard output cap (32 MiB) to bound memory usage and mitigate decompression-bomb inputs
Deduplication
Content-addressed deduplication uses keyed ChunkId values (BLAKE2b-256 MAC). Identical plaintext produces the same ChunkId, so the second copy is not stored; only refcounts are incremented.
vykar supports three index modes for dedup lookups:
- Full index mode — in-memory
ChunkIndex(HashMap<ChunkId, ChunkIndexEntry>) - Dedup-only mode — lightweight
DedupIndex(ChunkId -> stored_size) plusIndexDeltafor mutations - Tiered dedup mode —
TieredDedupIndex:- session-local HashMap for new chunks in the current backup
- Xor filter (
xorf::Xor8) as probabilistic negative check - mmap-backed on-disk dedup cache for exact lookup
During backup, enable_tiered_dedup_mode() is used by default. If the mmap cache is missing/stale/corrupt, vykar safely falls back to dedup-only HashMap mode.
Two-level dedup check (in Repository::bump_ref_if_exists):
- Persistent dedup tier — full index, dedup-only index, or tiered dedup index (depending on mode)
- Pending pack writers — blobs buffered in data/tree
PackWriters that have not yet been flushed
This prevents duplicates both across backups and within a single backup run.
Serialization
All persistent data structures use msgpack via rmp_serde. Structs serialize as positional arrays (not named-field maps) for compactness. This means field order matters — adding or removing fields requires careful versioning, and #[serde(skip_serializing_if)] must not be used on Item fields (it would break positional deserialization of existing data).
RepoObj Envelope
Every object stored in the repository is wrapped in a RepoObj envelope (repo/format.rs). The wire format depends on the encryption mode:
Encrypted: [1-byte type_tag][12-byte nonce][ciphertext + 16-byte AEAD tag]
Plaintext: [1-byte type_tag][plaintext]
The type tag identifies the object kind via the ObjectType enum:
| Tag | ObjectType | Used for |
|---|---|---|
| 0 | Config | Repository configuration (stored unencrypted) |
| 1 | Manifest | Snapshot list |
| 2 | SnapshotMeta | Per-snapshot metadata |
| 3 | ChunkData | Compressed file/item-stream chunks |
| 4 | ChunkIndex | Chunk-to-pack mapping |
| 5 | PackHeader | Reserved legacy tag (current pack files have no trailing header object) |
| 6 | FileCache | File-level cache (inode/mtime skip) |
| 7 | PendingIndex | Transient crash-recovery journal |
The type tag byte is always included in AAD (authenticated additional data). For identity-bound objects, AAD also includes a domain-separated object context, binding ciphertext to both object type and identity (for example, ChunkData to its ChunkId, SnapshotMeta to snapshot ID, and manifest/index to fixed context labels).
Repository Format
On-Disk Layout
<repo>/
|- config # Repository metadata (unencrypted msgpack)
|- keys/repokey # Encrypted master key (Argon2id-wrapped; absent in `none` mode)
|- manifest # Encrypted snapshot list
|- index # Encrypted chunk index
|- snapshots/<id> # Encrypted snapshot metadata
|- sessions/<id>.json # Session presence markers (concurrent backups)
|- sessions/<id>.index # Per-session crash-recovery journals (absent after clean backup)
|- packs/<xx>/<pack-id> # Pack files containing compressed+encrypted chunks (256 shard dirs)
`- locks/ # Advisory lock files
Local Optimization Caches (Client Machine)
These files live under a per-repo local cache root. By default this is the platform cache directory + vykar (for example, ~/.cache/vykar/<repo_id_hex>/... on Linux, ~/Library/Caches/vykar/<repo_id_hex>/... on macOS). If cache_dir is set in config, that path becomes the cache root. These are optimization artifacts, not repository source of truth.
<cache>/<repo_id_hex>/
|- filecache # File metadata -> cached ChunkRefs
|- dedup_cache # Sorted ChunkId -> stored_size (mmap + xor filter)
|- restore_cache # Sorted ChunkId -> pack_id, pack_offset, stored_size (mmap)
`- full_index_cache # Sorted full index rows for incremental index updates
All three index caches are validated against manifest.index_generation. A generation mismatch means “stale cache” and triggers safe fallback/rebuild paths.
The same per-repo cache root is also used as the preferred temp location for intermediate files (e.g. cache rebuilds).
Key Data Structures
ChunkIndex — HashMap<ChunkId, ChunkIndexEntry>, stored encrypted at the index key. The central lookup table for deduplication, restore, and compaction.
| Field | Type | Description |
|---|---|---|
| refcount | u32 | Number of snapshots referencing this chunk |
| stored_size | u32 | Size in bytes as stored (compressed + encrypted) |
| pack_id | PackId | Which pack file contains this chunk |
| pack_offset | u64 | Byte offset within the pack file |
Manifest — the encrypted snapshot list stored at the manifest key.
| Field | Type | Description |
|---|---|---|
| version | u32 | Format version (currently 1) |
| timestamp | DateTime | Last modification time |
| snapshots | Vec<SnapshotEntry> | One entry per snapshot |
| index_generation | u64 | Cache-validity token rotated when index changes; used to validate local mmap caches |
Each SnapshotEntry contains: name, id (32-byte random), time, source_label, label, source_paths.
SnapshotMeta — per-snapshot metadata stored at snapshots/<id>.
| Field | Type | Description |
|---|---|---|
| name | String | User-provided snapshot name |
| hostname | String | Machine that created the backup |
| username | String | User that ran the backup |
| time / time_end | DateTime | Backup start and end timestamps |
| chunker_params | ChunkerConfig | CDC parameters used for this snapshot |
| item_ptrs | Vec<ChunkId> | Chunk IDs containing the serialized item stream |
| stats | SnapshotStats | File count, original/compressed/deduplicated sizes |
| source_label | String | Config label for the source |
| source_paths | Vec<String> | Directories that were backed up |
| label | String | User-provided annotation |
Item — a single filesystem entry within a snapshot’s item stream.
| Field | Type | Description |
|---|---|---|
| path | String | Relative path within the backup |
| entry_type | ItemType | RegularFile, Directory, or Symlink |
| mode | u32 | Unix permission bits |
| uid / gid | u32 | Owner and group IDs |
| user / group | Option<String> | Owner and group names |
| mtime | i64 | Modification time (nanoseconds since epoch) |
| atime / ctime | Option<i64> | Access and change times |
| size | u64 | Original file size |
| chunks | Vec<ChunkRef> | Content chunks (regular files only) |
| link_target | Option<String> | Symlink target |
| xattrs | Option<HashMap> | Extended attributes |
ChunkRef — reference to a stored chunk, used in Item.chunks:
| Field | Type | Description |
|---|---|---|
| id | ChunkId | Content-addressed chunk identifier |
| size | u32 | Uncompressed (original) size |
| csize | u32 | Stored size (compressed + encrypted) |
Pack Files
Chunks are grouped into pack files (~32 MiB) instead of being stored as individual files. This reduces file count by 1000x+, critical for cloud storage costs (fewer PUT/GET ops) and filesystem performance (fewer inodes).
Pack File Format
[8B magic "VGERPACK"][1B version=1]
[4B blob_0_len LE][blob_0_data]
[4B blob_1_len LE][blob_1_data]
...
[4B blob_N_len LE][blob_N_data]
- Per-blob length prefix (4 bytes): enables forward scanning of all blobs from byte 9 to EOF
- Each blob is a complete RepoObj envelope:
[1B type_tag][12B nonce][ciphertext+16B AEAD tag] - Each blob is independently encrypted (can read one chunk without decrypting the whole pack)
- No trailing per-pack header object; pack analysis/compaction enumerate blobs via length-prefix scan
- Pack ID = unkeyed BLAKE2b-256 of entire pack contents, stored at
packs/<shard>/<hex_pack_id>
Data Packs vs Tree Packs
Two separate PackWriter instances:
- Data packs — file content chunks. Dynamic target size. Assembled in heap
Vec<u8>buffers. - Tree packs — item-stream metadata. Fixed at
min(min_pack_size, 4 MiB)and assembled in heapVec<u8>buffers.
Dynamic Pack Sizing
Pack sizes grow with repository size. Config exposes floor and ceiling:
repositories:
- path: /backups/repo
min_pack_size: 33554432 # 32 MiB (floor, default)
max_pack_size: 201326592 # 192 MiB (default)
Data pack sizing formula:
target = clamp(min_pack_size * sqrt(num_data_packs / 50), min_pack_size, max_pack_size)
max_pack_size has a hard ceiling of 512 MiB. Values above that are rejected at repository init/open.
| Data packs in repo | Target pack size |
|---|---|
| < 50 | 32 MiB (floor) |
| 200 | 64 MiB |
| 800 | 128 MiB |
| 1,800+ | 192 MiB (default cap) |
If you raise max_pack_size, target size can grow further, up to the 512 MiB hard ceiling.
num_data_packs is computed at open() by counting distinct pack_id values in the ChunkIndex (zero extra I/O). During a backup session, the target is recalculated after each data-pack flush, so the first large backup benefits from scaling immediately.
Data Flow
Backup Pipeline
The backup runs in two phases so multiple clients can upload concurrently (see Concurrent Multi-Client Backups).
── Phase 1: Upload (no exclusive lock) ──
generate session_id (128-bit random hex)
register_session() → write sessions/<session_id>.json, probe for active lock
open repo (full index loaded once)
begin_write_session(session_id) → journal key = sessions/<session_id>.index
→ prune stale local file-cache entries
→ recover own sessions/<session_id>.index if present (batch-verify packs, promote into dedup structures)
→ enable tiered dedup mode (mmap cache + xor filter, fallback to dedup HashMap)
→ configure bounded upload concurrency + pipeline limits
→ walk sources with excludes + one_file_system + exclude_if_present
→ cache-hit path: reuse cached ChunkRefs and bump refs
→ cache-miss path:
→ pipeline path (if pipeline_depth > 0):
→ walk emits regular files and segmented large files
(segmentation applies when file_size > segment_size;
effective segment size is clamped to min(segment_size_mib, pipeline_buffer_mib))
→ worker threads read/chunk/hash and classify each chunk:
- xor prefilter says "maybe present" → hash-only chunk
- xor prefilter miss (or no filter) → compress + encrypt prepacked chunk
→ sequential consumer validates segment order, performs dedup checks
(persistent dedup tier + pending pack writers), commits new chunks,
and handles xor false positives via inline transform
→ ByteBudget enforces pipeline_buffer_mib as a hard in-flight memory cap
→ sequential fallback path (pipeline_depth == 0)
→ serialize items incrementally into item-stream chunks (tree packs)
→ write SnapshotMeta at snapshots/<id>
── Phase 2: Commit (exclusive lock, brief) ──
acquire_lock_with_retry(10 attempts, 500ms base, exponential backoff + jitter)
commit_concurrent_session():
→ flush packs/pending uploads (pack flush triggers: target size, 10,000 blobs, or 300s age)
→ record T0 generation from in-memory manifest
→ reload fresh manifest from storage
→ check snapshot name uniqueness against fresh manifest
→ fast path (t0_generation == fresh manifest.index_generation):
→ verify_delta_packs (confirm new pack files exist on storage)
→ try_incremental_index_update (mmap cache merge)
→ on cache miss: reload full index + apply delta
→ slow path (generation mismatch — another client committed since T0):
→ reload full index from storage
→ delta.reconcile(fresh_index): new_entries already present → refcount bumps;
missing bump targets → Err(StaleChunksDuringCommit)
→ verify_delta_packs on reconciled delta
→ apply reconciled delta to fresh index
→ persist index first, then manifest (index-first ordering)
→ rebuild local dedup/restore/full-index caches as needed
→ persist local file cache
deregister_session() → delete sessions/<session_id>.json (while holding lock)
release_lock()
clear sessions/<session_id>.index
── Error Paths ──
→ on VykarError::Interrupted (Ctrl-C):
→ flush_on_abort(): seal partial packs, join upload threads, write final sessions/<id>.index
→ deregister_session(), release advisory lock, exit code 130
→ on soft file error (PermissionDenied / NotFound before commit):
→ skip file, increment snapshot.stats.errors, continue
→ exit code 3 (partial success) if any files were skipped
Restore Pipeline
open repository without index (`open_without_index`)
→ resolve snapshot
→ try mmap restore cache (validated by manifest.index_generation)
→ load item stream:
→ preferred: lookup tree-pack chunk locations via restore cache
→ fallback: load full index and read item stream normally
→ stream-decode items in two passes:
→ pass 1 create directories
→ pass 2 create symlinks and plan file chunk writes
→ build coalesced pack read groups:
→ preferred: index-free lookup via restore cache
→ fallback: load full index and retain only snapshot-needed chunks
→ parallel coalesced range reads by pack/offset
(merge when gap <= 256 KiB and merged range <= 16 MiB)
→ 6 reader workers fetch groups, decrypt + decompress-with-size-hint chunks
→ validate plaintext size and write to all targets (max 16 open files per worker)
→ restore file metadata (mode, mtime, optional xattrs)
Item Stream
Snapshot metadata (the list of files, directories, and symlinks) is not stored as a single monolithic blob. Instead:
- Items are serialized one-by-one as msgpack and appended to an in-memory buffer
- When the buffer reaches ~128 KiB, it is chunked and stored as a tree pack chunk (with a finer CDC config: 32 KiB min / 128 KiB avg / 512 KiB max)
- The resulting
ChunkIdvalues are collected intoitem_ptrsin theSnapshotMeta
This design means the item stream benefits from deduplication — if most files are unchanged between backups, the item-stream chunks are mostly identical and deduplicated away.
Restore now also consumes item streams incrementally (streaming deserialization) instead of materializing full Vec<Item> state up front.
When the mmap restore cache is valid, item-stream chunk lookups can avoid loading the full chunk index.
Operations
Locking
vykar uses a two-tier locking model to allow concurrent backup uploads while serializing commits and maintenance.
Session Markers (shared, non-exclusive)
During the upload phase of a backup, a lightweight JSON marker is written to sessions/<session_id>.json. Multiple backup clients can coexist in this tier simultaneously — session markers do not block each other.
Each marker contains: hostname, PID, registered_at, and last_refresh. On registration, the client probes for an active advisory lock (3 retries, 2 s base delay, exponential backoff + 25 % jitter). If the lock is held (maintenance in progress), the session marker is deleted and the backup aborts with Locked.
Session markers are refreshed approximately every 15 minutes (maybe_refresh_session() called from the upload pipeline). Markers older than 72 hours are treated as stale.
Advisory Lock (exclusive)
- Preferred path: backend-native lock APIs (
acquire_advisory_lock/release_advisory_lock) when the backend supports them (for example, vykar-server) - Fallback path: lock files at
locks/<timestamp>-<uuid>.json - Each lock contains: hostname, PID, and acquisition timestamp
- Oldest-key-wins: after writing its lock, a client lists all locks — if its key isn’t lexicographically first, it deletes its own lock and returns an error
- Stale cleanup: locks older than 6 hours are automatically removed before each acquisition attempt
- Recovery:
vykar break-lockforcibly removes stale backend/object locks when interrupted processes leave lock conflicts
The advisory lock is used for:
- Backup commit phase: acquired with
acquire_lock_with_retry(10 attempts, 500 ms base delay, exponential backoff + 25 % jitter). Held only for the brief commit — typically seconds. - Maintenance commands (
delete,prune,compact): acquired viawith_maintenance_lock(), which additionally cleans stale sessions (72 h), removes companion.indexjournal files and orphaned.indexfiles, then checks for remaining active sessions. If any non-stale sessions exist, the lock is released andVykarError::ActiveSessionsis returned — this prevents compaction from deleting packs that upload-phase backups depend on.
Command Summary
| Command | Upload phase | Commit/mutate phase |
|---|---|---|
backup | Session marker only (shared) | Advisory lock (exclusive, brief) |
delete, prune, compact | — | Maintenance lock (exclusive + session check) |
list, restore, check, info | — | No lock (read-only) |
When using a vykar server, server-managed locks with TTL replace client-side advisory locks (see Server Internals).
Signal Handling
Two-stage signal handling applies to all commands:
- First SIGINT/SIGTERM sets a global shutdown flag; iterative loops (
backup,prune,compact) check it and returnVykarError::Interrupted - Second signal restores the default handler (immediate kill)
- On backup abort:
flush_on_abort()seals partial packs, joins upload threads, writes finalsessions/<id>.indexjournal for recovery - Advisory lock is released before exit; CLI exits with code 130
Daemon Mode
vykar daemon runs scheduled backup cycles as a foreground process (no cron dependency).
- Scheduling: sleep-loop with configurable interval (
schedule.everyhuman-duration string, e.g."6h"). Optional random jitter (jitter_seconds) spreads load across hosts. - Cycle:
backup → prune → compact → checkper repo, sequential. Shutdown flag checked between steps. - Passphrase: daemon validates at startup that all encrypted repos have a non-interactive passphrase source (
passcommand,passphrase, orVYKAR_PASSPHRASEenv). Cannot prompt interactively.
Configuration:
schedule:
enabled: true
every: "6h"
on_startup: false
jitter_seconds: 0
Refcount Lifecycle
Chunk refcounts track how many snapshots reference each chunk, driving the dedup → delete → compact lifecycle:
- Backup —
store_chunk()adds a new entry with refcount=1, or increments an existing entry’s refcount on dedup hit - Delete / Prune —
ChunkIndex::decrement()decreases the refcount; entries reaching 0 are removed from the index - Orphaned blobs — after delete/prune, the encrypted blob data remains in pack files (the index no longer points to it, but the bytes are still on disk)
- Compact — rewrites packs to reclaim space from orphaned blobs
This design means delete is fast (just index updates), while space reclamation is deferred to compact.
Crash Recovery
If a backup is interrupted after packs have been flushed but before commit, those packs would be orphaned. The pending index journal prevents re-uploading their data on the next run:
- During backup, every 8 data-pack flushes, vykar writes a
sessions/<session_id>.indexblob to storage containing pack→chunk mappings for all flushed packs in this session - On the next backup with the same session ID, if the journal exists, packs are batch-verified by listing shard directories (avoiding per-pack HEAD requests on REST/S3 backends)
- Verified chunks are promoted into the dedup structures so subsequent dedup checks find them
- After a successful commit, the
sessions/<session_id>.indexblob is deleted flush_on_abort()writes a final journal before exiting, maximizing recovery coverage
If a backup process crashes or is killed without clean shutdown, its session marker (sessions/<id>.json) remains on storage. Maintenance commands (compact, delete, prune) will see it via list_sessions() and refuse to run until the marker ages out. cleanup_stale_sessions() removes markers older than 72 hours along with their companion .index journal files. Orphaned .index files whose .json marker no longer exists are also cleaned up.
Concurrent Multi-Client Backups
Multiple machines or scheduled jobs can back up to the same repository concurrently. The expensive work (walking files, compressing, encrypting, uploading packs) runs in parallel across all clients without coordination. Only the brief index+manifest commit requires mutual exclusion.
Session Lifecycle
Each backup client registers a session marker at sessions/<session_id>.json before opening the repository. The marker is refreshed approximately every 15 minutes during upload (maybe_refresh_session() called from the upload pipeline). At commit time, the client acquires the exclusive advisory lock, commits its changes, deregisters the session (while still holding the lock), then releases the lock.
Each session’s crash-recovery journal is co-located at sessions/<session_id>.index, keeping all per-session state in a single directory.
Why Sessions Block Maintenance but Not Each Other
Two concurrent backups do not block each other during upload — each operates on a private IndexDelta and private sessions/<id>.index journal. Maintenance commands (compact, delete, prune) must block on active sessions because compaction can delete packs that upload-phase clients are still referencing. with_maintenance_lock() acquires the advisory lock, cleans stale sessions, then fails with ActiveSessions if any remain.
IndexDelta Reconciliation
Each backup session accumulates index mutations in an IndexDelta: new_entries (newly uploaded chunks) and refcount_bumps (dedup hits on existing chunks). At commit time, the delta is reconciled against the current on-storage index:
- If the
manifest.index_generationis unchanged since session open (T0), no concurrent commits occurred — the delta is applied directly via the fast path (incremental mmap cache merge, or full index reload + apply). - If the generation changed (slow path), the full index is reloaded from storage and the delta is reconciled:
new_entriesfor chunks already present in the fresh index (another client uploaded the same chunk) are converted torefcount_bumpsrefcount_bumpsreferencing chunks no longer in the index (deleted by a concurrent maintenance operation) causeStaleChunksDuringCommit— the backup must be retried
- Pack verification (
verify_delta_packs) runs after reconciliation to avoid false negatives when chunks were absorbed as refcount bumps.
Index-First Persistence
The index is always written before the manifest. A crash between these two writes leaves orphan entries in the index (no snapshot references them) — harmless, cleaned up by the next compact. The reverse order would be unsafe: a manifest referencing chunks not yet in the index would cause restore failures.
Compact
After delete or prune, chunk refcounts are decremented and entries with refcount 0 are removed from the ChunkIndex — but the encrypted blob data remains in pack files. The compact command rewrites packs to reclaim this wasted space.
Algorithm
Phase 1 — Analysis (read-only, no pack downloads):
- Enumerate all pack files across 256 shard dirs (
packs/00/throughpacks/ff/) - Query each pack’s size via metadata-only calls (
HEAD/stat), parallelized (16 threads remote, 4 local) - Compute live bytes per pack from the
ChunkIndex:live_bytes = Σ(4 + stored_size)for each indexed blob in that pack - Derive
dead_bytes = (pack_size - PACK_HEADER_SIZE) - live_bytes; packs wherelive_bytes > pack_payloadare marked corrupt - Compute
unused_ratio = dead_bytes / pack_sizeper pack - Track pack health counters (
packs_corrupt,packs_orphan) in addition to live/dead bytes - Filter packs where
unused_ratio >= threshold
Phase 2 — Repack:
For each candidate pack (most wasteful first, respecting --max-repack-size cap):
- If backend supports
server_repack, send a repack plan and apply returned pack remaps - Otherwise run client-side repack:
- If all blobs are dead → delete the pack file directly
- Else validate pack header (magic + version) via
get_range(0..9)and cross-check each on-disk blob length prefix against the index’sstored_size - Read live blobs as encrypted passthrough (no decrypt/re-encrypt cycle), write a new pack, update index mappings
- Persist index/manifest updates before old pack deletion (
save_state()) - Delete old pack(s)
Crash Safety
The index never points to a deleted pack. Sequence: write new pack → save index → delete old pack. A crash between steps leaves an orphan old pack (harmless, cleaned up on next compact).
CLI
vykar compact [--threshold N] [--max-repack-size 2G] [-n/--dry-run]
Parallel Pipeline
Backup uses a bounded pipeline:
- Sequential walk stage emits file work
- Parallel workers in a crossbeam-channel pipeline read/chunk/hash files and classify chunks (hash-only vs prepacked)
- A
ByteBudgetenforces a hard cap on in-flight pipeline bytes (pipeline_buffer_mib) - Consumer stage commits chunks and updates dedup/index state sequentially (including segment-order validation for large files)
- Pack uploads run in background with bounded in-flight upload concurrency
Large files are split into fixed-size segments and processed through the same worker pool. Segmentation applies only when file_size > segment_size, and the effective segment size is clamped to pipeline_buffer_mib.
Configuration:
limits:
cpu:
max_threads: 4 # worker budget (0 = all cores)
nice: 10 # Unix nice value
max_upload_concurrency: 2 # default max in-flight background pack uploads
transform_batch_mib: 32 # flush threshold for pending transforms
transform_batch_chunks: 8192 # flush threshold by action count
pipeline_depth: 4 # 0 disables pipeline, >0 enables bounded pipeline
pipeline_buffer_mib: 256 # hard cap for in-flight pipeline bytes
segment_size_mib: 64 # large-file split threshold (16..=256), clamped by pipeline_buffer_mib
io:
read_mib_per_sec: 100 # disk read rate limit (0 = unlimited)
Why This Is Notable for Backup Tools
Deduplicating backup tools are often dominated by index memory and restore-planning overhead at large chunk counts. vykar’s implemented architecture addresses that class of bottlenecks with:
- Tiered dedup lookups (session map + xor filter + mmap cache) instead of always materializing a full in-memory index during backup
- Pending-index journal for crash recovery — interrupted backups resume without re-uploading flushed packs
- Index-light restore planning (restore-cache-first, filtered-index fallback) for lower peak memory on restore
- Explicitly bounded backup pipeline memory (
pipeline_buffer_mib) and bounded in-flight uploads - Incremental index update paths that avoid rebuilding/uploading from a full in-memory index on every save
- Concurrent multi-client backup protocol where only the brief commit phase requires an exclusive lock — upload phases run in parallel across all clients
These optimizations are implementation choices in current vykar, not future roadmap items.
Roadmap
Planned
| Feature | Description | Priority |
|---|---|---|
| GUI Config Editing | Structured editing of the config in the GUI, currently only via YAML | High |
| Linux GUI packaging | Native .deb/.rpm packages and a repository for streamlined installation | High |
| Windows GUI packaging | MSI installer and/or winget package for first-class Windows support | High |
| Snapshot filtering | By host, tag, path, date ranges | Medium |
| Async I/O | Non-blocking storage operations | Medium |
| JSON output mode | Structured JSON output for all CLI commands to enable scripting and integration with monitoring tools | Medium |
| Per-token permissions | Expand permissions from full/append-only to also limit reading and maintenance | Medium |
Implemented
| Feature | Description |
|---|---|
| Pack files | Chunks grouped into ~32 MiB packs with dynamic sizing, separate data/tree packs |
| Retention policies | keep_daily, keep_weekly, keep_monthly, keep_yearly, keep_last, keep_within |
| snapshot delete command | Remove individual snapshots, decrement refcounts |
| prune command | Apply retention policies, remove expired snapshots |
| check command | Structural integrity + optional --verify-data for full content verification |
| Type-safe PackId | Newtype for pack file identifiers with storage_key() |
| compact command | Rewrite packs to reclaim space from orphaned blobs after delete/prune |
| REST server | axum-based backup server with auth, append-only, quotas, freshness tracking, lock TTL, server-side compaction |
| REST backend | StorageBackend over HTTP with range-read support |
| Tiered dedup index | Backup dedup via session map + xor filter + mmap dedup cache, with safe fallback to HashMap dedup mode |
| Restore mmap cache | Index-light restore planning via local restore cache; fallback to filtered full-index loading when needed |
| Incremental index update | save_state() fast path merges IndexDelta into local full-index cache and serializes index from cache |
| Bounded parallel pipeline | Byte-budgeted pipeline (pipeline_buffer_mib) with bounded worker/upload concurrency |
| mmap-backed pack assembly | Data-pack assembly uses mmap-backed temp files (with fallback chain) to reduce heap residency under memory pressure |
| cache_dir override | Configurable root for file cache, dedup/restore/full-index caches, and preferred mmap temp-file location |
| Parallel transforms | rayon-backed compression/encryption within the bounded pipeline |
| break-lock command | Forced stale-lock cleanup for backend/object lock recovery |
| Compact pack health accounting | Compact analysis reports/tracks corrupt and orphan packs in addition to reclaimable dead bytes |
| File-level cache | inode/mtime/ctime skip for unchanged files — avoids read, chunk, compress, encrypt. Keys are 16-byte BLAKE2b path hashes (with transparent legacy migration). Stored locally under the per-repo cache root (default platform cache dir + vykar, or cache_dir override). |
| Daemon mode | vykar daemon runs scheduled backup→prune→compact→check cycles with two-stage signal handling |
| Server-side pack verification | vykar check delegates pack integrity checks to vykar-server when available; --distrust-server opts out |
| Upload integrity | REST PUT includes X-Content-BLAKE2b header; server verifies during streaming write |
| vykar-protocol crate | Shared wire-format types and pack/protocol version constants between client and server |
| Type-safe SnapshotId | Newtype for snapshot identifiers with storage_key() (ManifestId dropped — manifest is a singleton) |
Setup
Vykar includes a dedicated backup server for secure, policy-enforced remote backups. TLS is handled by a reverse proxy (nginx, caddy, and similar tools).
Why a dedicated REST server instead of plain S3
Dumb storage backends (S3, WebDAV, SFTP) work well for basic backups, but they cannot enforce policy or do server-side work. vykar-server adds capabilities that object storage alone cannot provide.
| Capability | S3 / dumb storage | vykar-server |
|---|---|---|
| Append-only mode | Not enforceable; a compromised client with S3 credentials can delete anything | Rejects delete and pack overwrite operations |
| Server-side compaction | Client must download and re-upload all live blobs | Server repacks locally on disk from a compact plan |
| Quota enforcement | Requires external bucket policy/IAM setup | Built-in byte quota checks on writes |
| Backup freshness monitoring | Requires external polling and parsing | Tracks last_backup_at on manifest writes |
| Lock auto-expiry | Advisory locks can remain after crashes | TTL-based lock cleanup in the server |
| Upload integrity | Relies on S3 Content-MD5 | Uses existing BLAKE2b checksum |
| Structural health checks | Client has to fetch data to verify structure | Server validates repository shape directly |
All data remains client-side encrypted. The server never has the encryption key and cannot read backup contents.
Install
Download a binary for your platform from the releases page.
Server configuration
All settings are passed as CLI flags. The authentication token is read from the VYKAR_TOKEN environment variable (kept out of process arguments to avoid exposure in ps output).
CLI flags
| Flag | Default | Description |
|---|---|---|
-l, --listen | localhost:8585 | Address to listen on |
-d, --data-dir | /var/lib/vykar | Root directory for the repository |
--append-only | false | Reject DELETE and overwrite operations on pack files |
--log-format | pretty | Log output format: json or pretty |
--quota | 0 | Storage quota (500M, 10G, plain bytes). 0 = unlimited |
--lock-ttl-seconds | 3600 | Auto-expire locks after this many seconds |
--network-threads | 4 | Async threads for handling network connections |
--io-threads | 6 | Threads for blocking disk I/O (reads, writes, hashing) |
Environment variables
| Variable | Required | Description |
|---|---|---|
VYKAR_TOKEN | Yes | Shared bearer token for authentication |
Start the server
export VYKAR_TOKEN="some-secret-token"
vykar-server --data-dir /var/lib/vykar
Run as a systemd service
Create an environment file at /etc/vykar/vykar-server.env with restricted permissions:
sudo mkdir -p /etc/vykar
echo 'VYKAR_TOKEN=some-secret-token' | sudo tee /etc/vykar/vykar-server.env
sudo chmod 600 /etc/vykar/vykar-server.env
sudo chown vykar:vykar /etc/vykar/vykar-server.env
Create /etc/systemd/system/vykar-server.service:
[Unit]
Description=Vykar backup REST server
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
User=vykar
Group=vykar
EnvironmentFile=/etc/vykar/vykar-server.env
ExecStart=/usr/local/bin/vykar-server --data-dir /var/lib/vykar
Restart=on-failure
RestartSec=2
NoNewPrivileges=true
PrivateTmp=true
ProtectSystem=full
ProtectHome=true
ReadWritePaths=/var/lib/vykar
[Install]
WantedBy=multi-user.target
Then reload and enable:
sudo systemctl daemon-reload
sudo systemctl enable --now vykar-server.service
sudo systemctl status vykar-server.service
Reverse proxy
vykar-server listens on HTTP and expects a reverse proxy to handle TLS. Pack uploads can be up to 512 MiB, so the proxy must allow large request bodies.
Nginx
server {
listen 443 ssl http2;
server_name backup.example.com;
ssl_certificate /etc/letsencrypt/live/backup.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/backup.example.com/privkey.pem;
client_max_body_size 600m; # vykar-server allows up to 512 MiB
proxy_request_buffering off; # stream uploads directly to backend
location / {
proxy_pass http://127.0.0.1:8585;
}
}
Caddy
backup.example.com {
request_body {
max_size 600MB
}
reverse_proxy 127.0.0.1:8585
}
Client configuration (REST backend)
repositories:
- label: "server"
url: "https://backup.example.com"
access_token: "some-secret-token"
encryption:
mode: "auto"
sources:
- "/home/user/documents"
All standard commands (init, backup, list, info, restore, delete, prune, check, compact) work over REST without CLI workflow changes.
Health check
# No auth required
curl http://localhost:8585/health
Returns {"status": "ok", "version": "..."}. No authentication required.
Server Internals
Technical reference for vykar-server’s internal architecture: crate layout, REST API surface, authentication, policy enforcement, and server-side operations.
For deployment and configuration, see Setup.
Crate Layout
| Component | Location | Purpose |
|---|---|---|
| vykar-server | crates/vykar-server/ | axum HTTP server with all server-side features |
| vykar-protocol | crates/vykar-protocol/ | Shared wire-format types and pack/protocol version constants (no I/O or crypto deps) |
| RestBackend | crates/vykar-core/src/storage/rest_backend.rs | StorageBackend impl over HTTP |
REST API
Storage endpoints map 1:1 to the StorageBackend trait. The data_dir is the repository — there is no repo name in the URL.
| Method | Path | Maps to | Notes |
|---|---|---|---|
GET | /{*path} | get(key) | 200 + body or 404. With Range header → get_range (returns 206). |
HEAD | /{*path} | exists(key) | 200 (with Content-Length) or 404 |
PUT | /{*path} | put(key, data) | Raw bytes body. 201/204. Rejected if over quota. Pack uploads require X-Content-BLAKE2b header (BLAKE2b-256 hex); server verifies during streaming write. Non-pack objects: header optional. |
DELETE | /{*path} | delete(key) | 204 or 404. Rejected with 403 in append-only mode. |
GET | /{*path}?list | list(prefix) | JSON array of key strings |
POST | /{*path}?mkdir | create_dir(key) | 201 |
Admin endpoints:
| Method | Path | Description |
|---|---|---|
POST | /?init | Create repo directory scaffolding (256 shard dirs, etc.) |
POST | /?batch-delete | Body: JSON array of keys to delete |
POST | /?repack | Server-side compaction (see below) |
GET | /?stats | Size, object count, last backup timestamp, quota usage |
POST | /?verify-packs | Server-side pack integrity verification (BLAKE2b hash, header magic/version, blob boundaries) |
GET | /?verify-structure | Structural integrity check (pack magic, shard naming) |
GET | /health | Uptime, disk space, version (unauthenticated) |
Lock endpoints:
| Method | Path | Description |
|---|---|---|
POST | /locks/{id} | Acquire lock (body: {"hostname": "...", "pid": 123}) |
DELETE | /locks/{id} | Release lock |
GET | /locks | List active locks |
Authentication
Single shared bearer token, constant-time compared via the subtle crate. Set via the VYKAR_TOKEN environment variable.
GET /health is the only unauthenticated endpoint.
Append-Only Enforcement
When append_only = true:
DELETEon any path →403 ForbiddenPUTto existingpacks/**keys →403(no overwriting pack files)PUTtomanifest,index→ allowed (updated every backup)batch-delete→403repackwithdelete_after: true→403
This prevents a compromised client from destroying backup history.
Quota Enforcement
Storage quota (quota_bytes in config). Server tracks total bytes used (initialized by scanning data_dir on startup, updated on PUT/DELETE). When a PUT would exceed the limit → 413 Payload Too Large.
Backup Freshness Monitoring
The server detects completed backups by observing PUT /manifest (always the last write in a backup). Updates last_backup_at timestamp, exposed via the stats endpoint:
{
"total_bytes": 1073741824,
"total_objects": 234,
"total_packs": 42,
"last_backup_at": "2026-02-11T14:30:00Z",
"quota_bytes": 5368709120,
"quota_used_bytes": 1073741824
}
Lock Management with TTL
Server-managed locks replace advisory JSON lock files:
- Locks are held in memory with a configurable TTL (default 1 hour)
- A background task (tokio interval, every 60 seconds) removes expired locks
- Prevents orphaned locks from crashed clients
Server-Side Compaction (Repack)
The key feature that justifies a custom server. Pack files that have high dead-blob ratios are repacked server-side, avoiding multi-gigabyte downloads over the network.
How it works (no encryption key needed):
Pack files contain encrypted blobs. Compaction does encrypted passthrough — it reads blobs by offset and repacks them without decrypting.
- Client opens repo, downloads and decrypts the index (small)
- Client analyzes pack headers to identify live vs dead blobs (via range reads)
- Client sends
POST /?repackwith a plan:{ "operations": [ { "source_pack": "packs/ab/ab01cd02...", "keep_blobs": [ {"offset": 9, "length": 4096}, {"offset": 8205, "length": 2048} ], "delete_after": true } ] } - Server reads live blobs from disk, writes new pack files (magic + version + length-prefixed blobs, no trailing header), deletes old packs
- Server returns new pack keys and blob offsets so the client can update its index
- Client updates
ChunkIndexmappings and callssave_state
For packs with keep_blobs: [], the server simply deletes the pack.
Structural Integrity Check
GET /?verify-structure checks (no encryption key needed):
- Required files exist (
config,manifest,index,keys/repokey) - Pack files follow
<2-char-hex>/<64-char-hex>shard pattern - No zero-byte packs (minimum valid = magic 8 bytes + version 1 byte = 9 bytes)
- Pack files start with
VGERPACKmagic bytes - Reports stale lock count, total size, and pack counts
Full content verification (decrypt + recompute chunk IDs) can be done client- or server-side
- Server-side
vykar check --verify-data: This won’t download the whole repo, but instruct the server to checksum the actual data. - Client-side
vykar check --verify-data --distrust-server: This will download all the data and verify it client-side.
Server Configuration
All settings are passed as CLI flags. The authentication token is read from the VYKAR_TOKEN environment variable.
export VYKAR_TOKEN="some-secret-token"
vykar-server --data-dir /var/lib/vykar --append-only --log-format json --quota 10G --max-blocking-threads 6
See vykar-server --help for the full list of flags and defaults.
RestBackend (Client Side)
crates/vykar-core/src/storage/rest_backend.rs implements StorageBackend using ureq (sync HTTP client). Connection-pooled. Maps each trait method to the corresponding HTTP verb. get_range sends a Range: bytes=<start>-<end> header and expects 206 Partial Content. Also exposes extra methods beyond the trait: batch_delete(), repack(), verify_packs(), acquire_lock(), release_lock(), stats().
Client config:
repositories:
- label: server
url: https://backup.example.com
access_token: "secret-token-here"
Related: Setup, Architecture